Last Updated on December 20, 2025 by KnownSense
This article is about natural language processing, one of the most popular topics in the world recently. You can think of NLP as a roof for the tasks, such as sentiment analysis, topic segmentation, tokenization, text to speech, machine translation, and much more, and its story actually goes back to 1950s.
NLP Story
In 1954, IBM and Georgetown University achieved the first successful machine translation. They managed to translate more than 60 Russian sentences into English. A simple translation was made by converting the words into numerical codes, and the algorithm consisted entirely of handwritten rules. Others claimed that the machine translation would be a solved problem in 5 years, but it wasn’t because the rules approach was not comprehensive and effective enough, that’s why that period would be later known as symbolic NLP. Working with natural language has its own unique challenge, such as sarcasm, or irony, or ambiguity. The same words can have different meanings in different sentences, so you need to make sentiment analysis. Language itself is a chaotic structure, so what we need is a stochastic approach. In 1990s, statistical NLP evolved, and this was possible with the developed machine learning algorithms, an increase in computational resources. In addition, the amount of the data increased astronomically with the spread of the internet. In 2003, word n‑gram model, which is a pure statistical language model, was founded. The main idea was that we can find the probability of the next word by looking only at the previous words, so these are great improvements, but there was still a problem for computers to understand the meaning of the word. Then, Tomas Mikolov and co‑authors created and published something called Word2Vec. The paper was published in 2013, and that changed the NLP world entirely. We will talk about Word2Vec in more details, but briefly, it is the representation of the words with numbers in a vector so that the machines finally can understand the word meanings actually. And later on with the improvements about attention mechanism and transformer models, here we are today with large language models such as GPT and BERT. So, these are the milestones of NLP.
Prepare Text Data
Text data can be categorized into three main types.

Pre-processing
Text data type might affect your paths, but mostly in an LP, the first step is preprocessing because you want to clean it before any analysis or model building. Preprocessing can depend on your text data and the purpose of your use case. Let’s see some examples of preprocessing.
Before we start with the preprocessing example, remember that NLTK (Natural Language Toolkit) is a powerful Python library used for working with human language data in Natural Language Processing (NLP). It provides a wide range of tools for preprocessing, analyzing, and categorizing text. NLTK is widely used in both academic research and real-world applications that involve understanding and processing natural language.
Tokenization
Tokenization is splitting text into smaller units. Tokens can be words, smaller parts of words, or just characters. In below example, each words and punctuation marks represents a token. If you don’t want to include the punctuation marks, that’s another preprocessing step. This step can be useful for reducing the cost as it reduces the number of tokens. Also, if your data comes from web scripting there might be lots of unnecessary symbols.
import nltk
#sample text
text = """Researchers at the university are diliegently working to develope innovative solutions for global challaenge. They're exploring sustainable energy sources, advance medical technologies, and striving to understand the complexity of human behaviour."""from nltk.tokenize import word_tokenize
tokens = word_tokenize(text)
print("Tokens:" , tokens)Output:
Tokens: ['Researchers', 'at', 'the', 'university', 'are', 'diliegently', 'working', 'to', 'develope', 'innovative', 'solutions', 'for', 'global', 'challaenge', '.', 'They', "'re", 'exploring', 'sustainable', 'energy', 'sources', ',', 'advance', 'medical', 'technologies', ',', 'and', 'striving', 'to', 'understand', 'the', 'complexity', 'of', 'human', 'behaviour', '.']
Stop word removal
Another preprocessing step involves removing frequently used words that create noise and reduce efficiency.
from nltk.corpus import stopwords
nltk.download('stopwords')
stop_words = stopwords.words('english')
filtered_tokens = [word for word in tokens if word.lower() not in stop_words]
print(filtered_tokens )Output:
['Researchers', 'university', 'diliegently', 'working', 'develope', 'innovative', 'solutions', 'global', 'challaenge', '.', "'re", 'exploring', 'sustainable', 'energy', 'sources', ',', 'advance', 'medical', 'technologies', ',', 'striving', 'understand', 'complexity', 'human', 'behaviour', '.']
Stemming
In this step, the words are reduced to their root form. Stemming is widely used, but it may raise problems sometimes. For example, fishing and fisher both have the same root, but they have different meanings. Another important note is that the stemmed form may not always be a valid word. This depends on your output, but some of them are rule‑based and regenerate non‑real words.
from nltk.stem import PorterStemmer
ps = PorterStemmer()
stemmed_token = [ps.stem(word) for word in tokens if word not in filtered_tokens]
print(stemmed_token )Output:
['research', 'univers', 'dilieg', 'work', 'develop', 'innov', 'solut', 'global', 'challaeng', '.', 'they', "'re", 'explor', 'sustain', 'energi', 'sourc', ',', 'advanc', 'medic', 'technolog', ',', 'strive', 'understand', 'complex', 'human', 'behaviour', '.']
If you noticed, some words are converted correctly, but others (e.g., “univers”, “dilieg”, “solut”) become complete nonsense — that’s what stemming can do. Stemming is still useful for some applications (search engines, for example), but if you want only real words, use lemmatization.
Lemmatization
Lemmatization reduces words to their lemma, which is the correct base form found in a dictionary (e.g., “running” → “run”, “better” → “good”). Unlike stemming, it considers the word’s context and part of speech to determine the appropriate base form. Because it relies on linguistic rules and vocabulary lookups, it is more accurate but also more computationally intensive.
Like nltk, spacy is also an open-source Python library for advanced Natural Language Processing (NLP) designed for efficiency and production-ready applications.
import spacy
text = " ".join(filtered_token)
nlp = spacy.load("en_core_web_sm")
doc = nlp(text)
for token in doc:
print(token, "=>", token.lemma_)Output:
Researchers => researcher
university => university
diliegently => diliegently
working => work
develope => develope
innovative => innovative
solutions => solution
global => global
challaenge => challaenge
. => .
They => they
're => be
exploring => explore
sustainable => sustainable
energy => energy
sources => source
, => ,
advance => advance
medical => medical
technologies => technology
, => ,
striving => strive
understand => understand
complexity => complexity
human => human
behaviour => behaviour
. => .
Word Embedding
Computer scientists always tries to find a way to represent the words with numbers. Before word embeddings came along, there were methods.
One‑hot encoding is the simplest method. Each word in the vocabulary is represented by a vector with all zeros, except for a single one at the index corresponding to the words in the vocabulary.

Bag of words model represents, not only the vocabulary index, but also the presence of these words in documents by counting how many times the word appears in a document.

TF‑IDF improves that simple term frequency approach by taking into account also how common the word is across all documents.
These traditional methods were useful for certain applications, but had limitations since they cannot capture the semantic meaning of the words.
The idea is to keep the feature of the words with numbers. Let’s take below vector with eight numbers in this example (but normally, we have much larger vectors) where each number represents one feature.
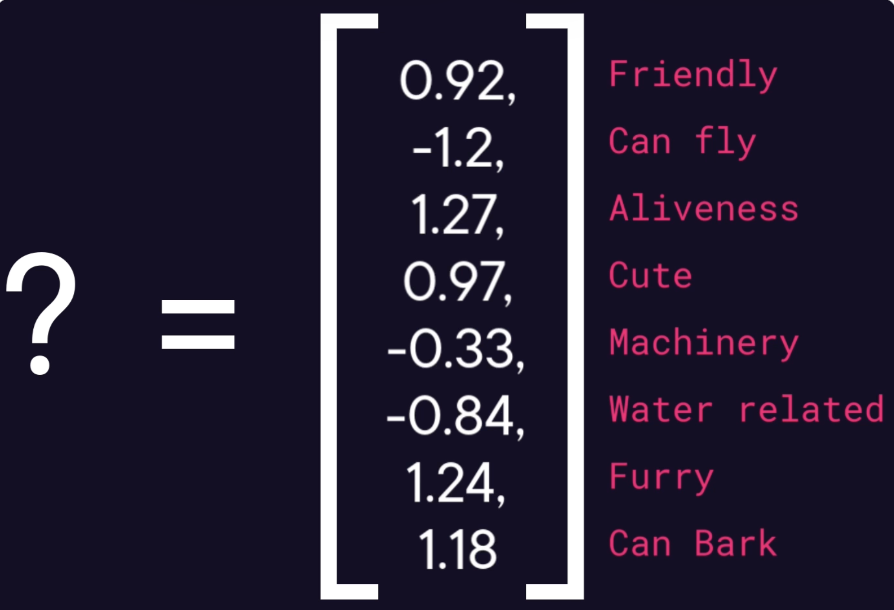
I claim that you don’t need to hear the word in order to understand it. I won’t tell you which word it is, I will just give you the numbers and the features. The first number shows that how friendly is this thing. Second number shows if this thing can fly. Third one is about aliveness and so on. Try to guess the word. Well, of course, the answer word is dog, and machines can understand this as well. Because once we give the vectors for all words, we are actually embedding these words into a point in the dimensional space.
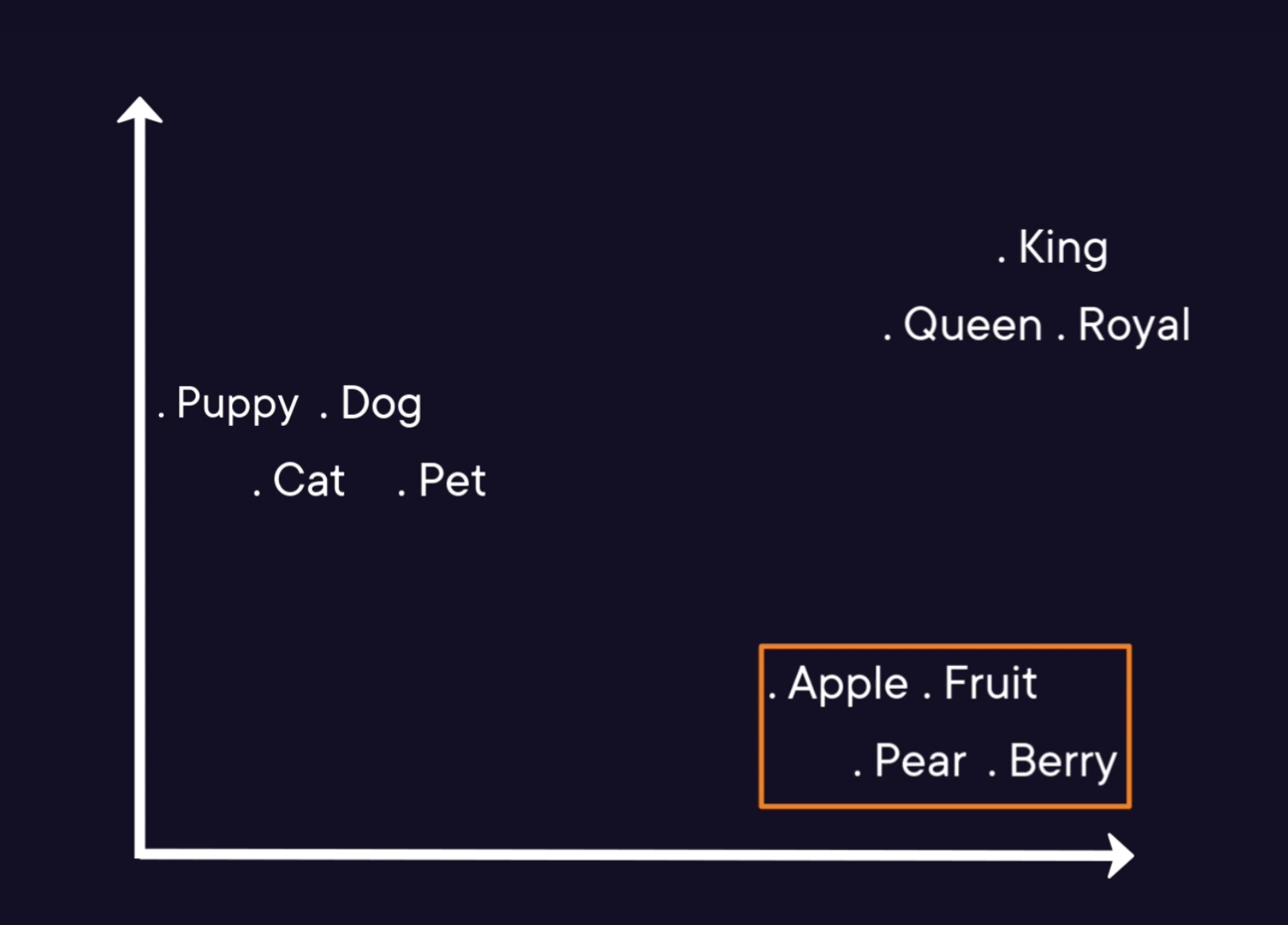
In this space, the words are closer to each other if their meanings are semantically similar, so computers can also perform operations with them.
We will explore embedding models, pre-trained embeddings, and other essential NLP topics in detail in upcoming articles.
Conclusion
To conclude, this article introduced the foundations of Natural Language Processing, tracing its journey from early rule-based methods to today’s advanced transformer models. We explored essential preprocessing steps such as tokenization, stop-word removal, stemming, and lemmatization, along with an overview of traditional and modern word-embedding techniques. Together, these concepts form the core building blocks that enable machines to understand and process human language effectively.