Last Updated on May 9, 2026 by KnownSense
Your AI model passes every test. It scores high on accuracy. It handles edge cases well. Then one day, it starts making bizarre mistakes — classifying spam as safe, approving fraudulent transactions, or misreading a road sign. What happened? Most likely, someone launched an adversarial attack on AI system.
In this guide, you will learn what adversarial attacks are, how attackers carry them out, what types exist, and most importantly, how to defend against them. Whether you build fraud detection systems, chatbots, or autonomous tools, this knowledge is essential.
What Are Adversarial Attacks?
Simply put, an adversarial attack is a deliberate attempt to fool a machine learning model by feeding it deceptive input. The attacker makes small, carefully calculated changes to the data — changes so subtle that a human would never notice them — but the AI model misinterprets the input entirely.
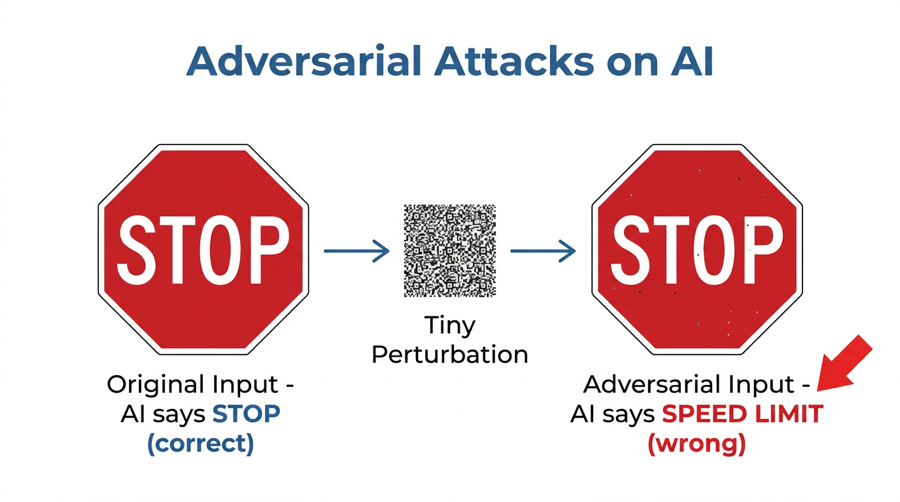
For example, imagine a self-driving car approaching a stop sign. An attacker places a few small stickers on the sign. To a human driver, it still clearly looks like a stop sign. However, the car’s vision model now reads it as a speed limit sign and drives straight through.
The core problem: AI models do not “see” or “understand” data the way humans do. They rely on mathematical patterns, and adversarial attacks exploit the gaps in those patterns. This is fundamentally different from traditional hacking. The attacker does not break into a server or steal a password. Instead, they manipulate the logic of the AI itself.
Why Should You Care About Adversarial Attacks?
As organizations integrate AI into critical workflows, adversarial attacks move from academic curiosity to real business risk. Here is why they matter:
- Financial loss: A fooled fraud detection model lets fraudulent transactions through, costing your business real money
- Safety hazards: In healthcare or autonomous vehicles, a wrong prediction can endanger lives
- Security bypass: Attackers can slip malware past AI-powered threat detection systems
- Reputation damage: Customers lose trust when your AI-driven product makes unexplainable errors
- Regulatory exposure: Regulators increasingly hold organizations accountable for AI failures
Moreover, these attacks are difficult to detect because the inputs often look perfectly normal to human reviewers. As a result, the damage can accumulate silently over weeks or months before anyone notices.
How Adversarial Attacks Differ from Traditional Cyberattacks
To understand why adversarial attacks require a different defense strategy, let’s compare them to traditional cyberattacks
| Aspect | Traditional Cyberattacks | Adversarial AI Attacks |
|---|---|---|
| Target | Software vulnerabilities, human error, network infrastructure | The AI model’s decision-making logic and training data |
| Method | Firewalls, antivirus, intrusion detection systems catch most attacks | standard security tools miss them because the inputs appear legitimate |
| Visibility | Damage is often immediate and obvious (data breach, service down) | Damage is subtle and gradual (silent accuracy degradation, biased outputs) |
| Recovery | Patch the vulnerability, restore from backup | Retrain the model, audit the data pipeline, redesign input validation |
The key takeaway: Your existing security stack — firewalls, antivirus, WAFs — will not catch adversarial attacks. You need AI-specific defenses.
How Adversarial Attacks Work: Step by Step
Adversarial attacks typically follow a four-stage process. Understanding each stage helps you identify where to place defenses.
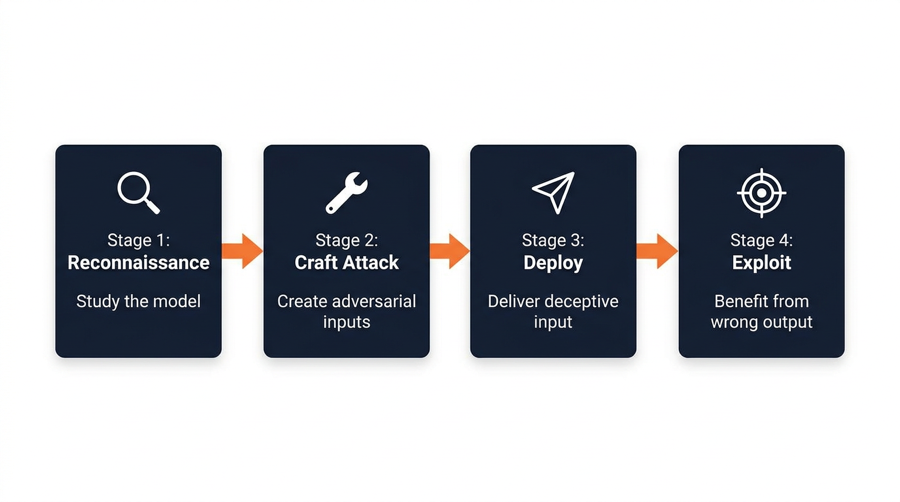
Stage 1: Reconnaissance
First, the attacker studies your AI system. They analyze how it responds to different inputs, what predictions it makes, and where its decision boundaries lie. In some cases, they reverse-engineer the model architecture. In others, they simply query your API thousands of times and observe the outputs.
Stage 2: Crafting the Attack
Next, the attacker creates adversarial inputs designed to exploit the weaknesses they discovered. These inputs contain carefully optimized perturbations — tiny changes that push the model’s prediction across a decision boundary. The changes are mathematically precise but visually or semantically invisible to humans.
Stage 3: Deployment
Then, the attacker delivers the adversarial input to the target system. This could happen through a user upload, an API call, a manipulated data feed, or even a physical change in the real world (like stickers on a stop sign). The AI model processes the input and produces the wrong output.
Stage 4: Exploitation
Finally, the attacker benefits from the model’s mistake. Depending on the use case, this could mean bypassing security, committing fraud, causing a misdiagnosis, or extracting sensitive information from the model.
Types of Adversarial Attacks
Not all adversarial attacks work the same way. They vary based on when they happen, what they target, and how much the attacker knows about your model. Here are the main categories:
1. Poisoning Attacks (Training Time)
When it happens: During model training. In a poisoning attack, the attacker injects malicious data into your training dataset. As a consequence, the model learns wrong patterns from the start. For instance, an attacker could add thousands of mislabeled spam emails to a training set, teaching the spam filter to ignore real spam in the future.
Why it’s dangerous: The model looks healthy on standard benchmarks. The corruption only shows up in specific, attacker-chosen scenarios.
2. Evasion Attacks (Inference Time)
When it happens: After the model is trained and deployed. In an evasion attack, the attacker modifies a single input to trick the live model. The model is already trained and working — the attacker simply crafts an input that falls on the wrong side of its decision boundary.
There are two subtypes:
- Untargeted evasion — The attacker wants any wrong answer. For example, making a malware file look benign to an antivirus model.
- Targeted evasion — The attacker wants a specific wrong answer. For example, making the model classify a cat image as a dog, not just “not a cat.”
3. Model Extraction Attacks (Stealing the Model)
When it happens: While the model serves predictions. Here, the attacker does not manipulate the model’s behavior. Instead, they send thousands of queries to your API and use the responses to build a copy of your model. Once they have a replica, they can study it offline to find vulnerabilities or use it without paying for your service.
Why it matters: Your model represents significant investment in data, compute, and expertise. Extraction attacks steal that intellectual property.
4. Inference Attacks (Data Theft)
When it happens: While the model serves predictions. In inference attacks, the attacker extracts sensitive information from the model’s outputs. Two common forms include:
- Model inversion — The attacker reconstructs training data from the model’s predictions. For example, recovering a person’s face from a facial recognition model.
- Membership inference — The attacker determines whether a specific data point was part of the training set. This can reveal private information about individuals.
5. Transfer Attacks (Cross-Model Exploitation)
When it happens: Anytime. An adversarial input crafted to fool one model often fools other models trained on similar data or architectures. As a result, an attacker can build adversarial examples against their own model and then use them against yours — even without access to your system.
Why it’s concerning: This means attackers do not need direct access to your model at all.
White-Box vs. Black-Box Attacks
Beyond attack type, another important distinction is how much the attacker knows about your model:
| Knowledge Level | What the Attacker Knows | Difficulty | Real-World Likelihood |
|---|---|---|---|
| White-box | Full access to model architecture, parameters, training data | Easier to craft precise attacks | Less common (requires insider access or leaked models) |
| Black-box | No internal access; only observes inputs and outputs | Harder but still effective | More common (API-based attacks, transfer attacks) |
| Gray-box | Partial knowledge (e.g., model type but not exact parameters) | Moderate difficulty | Common in competitive environments |
In practice, most real-world adversarial attacks are black-box. Attackers query your model through its API, study the responses, and iteratively craft inputs that cause misclassification. Therefore, even if you keep your model architecture secret, you are not safe.
Real-World Examples of Adversarial Attacks
To make this concrete, here are scenarios across different industries:
- Healthcare: An attacker subtly modifies a medical scan image so that a diagnostic AI misses a tumor. The image looks identical to a radiologist, but the model’s confidence in the “healthy” classification jumps from 51% to 98%.
- Finance: A fraud detection model processes thousands of transactions per second. An attacker learns the model’s patterns and crafts transactions that appear legitimate to the AI but are actually fraudulent — bypassing automated controls entirely.
- Cybersecurity: A malware author modifies their code just enough to evade an AI-powered antivirus. The malware still works as intended, but the security model now classifies it as safe software.
- Autonomous Vehicles: Researchers have demonstrated that small, carefully placed markings on road signs can cause vision models to misread them. A stop sign becomes a yield sign. A speed limit sign becomes unreadable.
- Natural Language Processing: An attacker changes a few characters in a phishing email (using homoglyphs or invisible Unicode characters) so that an NLP-based email filter classifies it as safe, allowing it to reach the target inbox.
How to Defend Against Adversarial Attacks
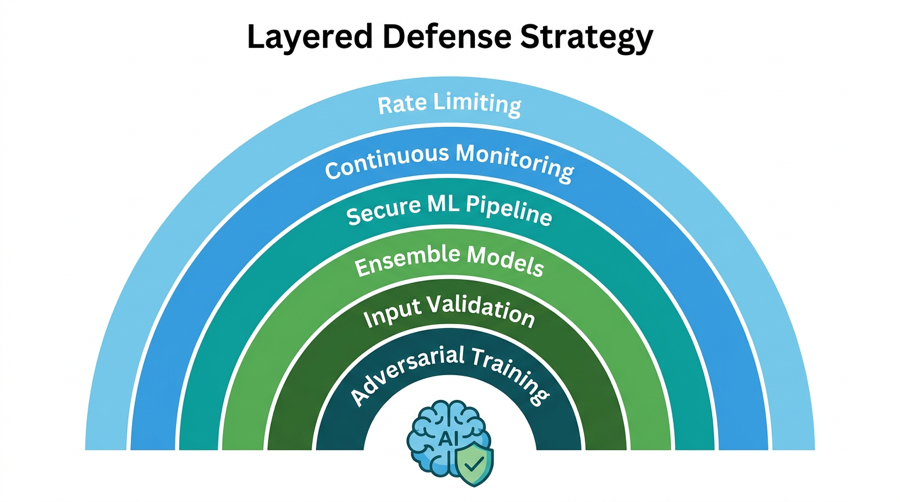
No single defense eliminates adversarial risk entirely. However, a layered strategy significantly raises the bar for attackers. Here are six proven defense techniques:
1. Adversarial Training
Train your model on both clean data and known adversarial examples. By exposing the model to deceptive inputs during training, it learns to recognize and resist them.
Trade-off: This approach increases training time and computational cost, but it produces a meaningfully more robust model.
2. Input Validation and Preprocessing
Add a validation layer before data reaches your model. Techniques include:
- Input normalization — Standardize inputs to reduce the effect of small perturbations
- Feature squeezing — Reduce the precision of input features (e.g., color depth in images) to eliminate subtle manipulations
- Noise filtering — Apply smoothing filters that remove adversarial perturbations without affecting legitimate data
3. Ensemble Models
Instead of relying on a single model, use multiple models that vote on each prediction. An adversarial input that fools one model is unlikely to fool all of them simultaneously. As a result, ensemble approaches significantly improve resilience.
4. Continuous Monitoring and Anomaly Detection
Monitor your model’s behavior in production. Watch for:
- Sudden drops in accuracy or confidence scores
- Unusual patterns in input data distribution
- Unexpected outputs for standard test cases
- Spikes in API query volume (potential extraction attack)
Set up automated alerts so your team can investigate anomalies immediately.
5. Secure the ML Pipeline End-to-End
Apply security practices across the entire machine learning lifecycle:
- Data provenance — Track where every piece of training data comes from
- Access control — Restrict who can modify training datasets and model parameters
- Version control — Maintain audit trails for every model version
- Least privilege — Give each component only the access it needs
6. Rate Limiting and Query Detection
To defend against model extraction and black-box attacks, limit how many queries a single user or IP can make. Additionally, monitor query patterns for signs of systematic probing — rapid-fire queries with small input variations are a strong signal.
Adversarial Attacks and the OWASP Top 10 for LLMs
If you have read our guide on the OWASP Top 10 Risks for LLMs, you will notice significant overlap with adversarial attacks:
| OWASP Risk | Adversarial Attack Connection |
|---|---|
| Prompt Injection | A form of evasion attack — the attacker crafts input to override model behavior |
| Data and Model Poisoning | Directly maps to poisoning attacks during training |
| Sensitive Information Disclosure | Inference attacks extract private data from model outputs |
| Misinformation | Adversarial inputs can force models to generate confident but wrong answers |
| Supply Chain Vulnerabilities | Poisoned pre-trained models or corrupted datasets in the supply chain |
In other words, adversarial attacks are the “how” behind many of the OWASP risks. Understanding both gives you a complete picture of AI security.
Quick-Start Checklist: Defending Your AI
Use this checklist to assess your current defenses:
- Include adversarial examples in your training pipeline
- Add input validation and preprocessing before model inference
- Use ensemble models for critical predictions
- Monitor model accuracy, confidence, and input distributions in production
- Rate-limit API access and detect systematic probing patterns
- Track data provenance for all training and fine-tuning datasets
- Restrict access to model parameters and training infrastructure
- Run regular red-team exercises against your AI systems
- Maintain version control and audit logs for every model update
- Build incident response runbooks for adversarial attack scenarios
Conclusion
In conclusion, adversarial attacks represent a fundamentally different threat than traditional cyberattacks. They target the logic of your AI model itself, not your servers or your network. Because these attacks use inputs that look perfectly normal to human reviewers, they can silently degrade your model’s performance for weeks before anyone notices. Therefore, defending against them requires a shift in mindset — from perimeter security to model-level resilience. By combining adversarial training, input validation, ensemble methods, continuous monitoring, and secure pipeline practices, you can significantly reduce your exposure and build AI systems that your users can trust.