Last Updated on December 20, 2025 by KnownSense
In Simple words, Embedding models are machine-learning models that convert content—text, images, audio, code—into numeric vectors. These vectors capture meaning, context, and relationships so that machines can compare and reason about them.
Embedding Models
Word2Vec model developed by Google team led by Tomas Mikolov and its two architectures, Continuous Bag of Words and Skip‑gram, were particularly effective and made the word embeddings practical on large scale that made word embeddings more popular than ever in NLP applications.
Another model, GloVe, was being developed by Stanford researchers. It’s another popular word embedding technique, and they differ fundamentally in their approach to generate embeddings. The main difference is that Word2Vec learns embeddings from looking at the surrounding words using a window approach and GloVe counts the frequency by using the entire corpus.
Another popular model is fastText created by Facebook’s AI research lab, it separates the words into subwords and train the model on top of these subwords. With this approach, it can also work well for the words that are not even in the training corpus.
There was the concept of word numbering before these models and there are other alternatives as well. However, these models are the most popular ones in terms of usage in today’s world.
Pretrained Embeddings
You may want to train your own embeddings if you have time and enough data, but you may also choose to use pre‑trained models. Let’s see how we can do that with examples.
Pre‑trained models are available to download across different sources. One way to do that is to use the gensim library. You can call load function and download available models.
!pip3 install gensimimport gensim.downloader as api
word2vec = api.load.('word2vec-google-news-300')glove = api.load.('glove-wiki-gigaword-300')fastext_model = api.load.('fasttext-wiki-news-subwords-300') In above example we downloaded Word2Vec, GloVe, and FastText models. Google News used for word2vec training, Wikipedia for glove and fasttext. There are other options like Twitter. and you can also use that models. In above examples, 300 stands for the area length. This means our word vectors will consist of 300 numbers.
Then, we can create word vectors. Let’s see how it looks like when we give the word apple.

It’s just an area of numbers. Similarly you can check for GloVe and fastText version. If we print the length of these vectors, we will see there are 300 numbers for each model. We can also check the similar words using most_similar function. It returns words that are closer in terms of distance in our vector space.
word2vec.most_similar.("apple")Output:
[('apples', 0.720359742641449),
('pear', 0.6450697183609009),
('fruit', 0.6410146355628967),
('berry', 0.6302294731140137),
('pears', 0.6133960485458374),
('strawberry', 0.6058261394500732),
('peach', 0.6025872230529785),
('potato', 0.5960935354232788),
('grape', 0.5935864448547363),
('blueberry', 0.5866668224334717)]
Alright, Let’s try the some common example.
result_vector = word2vec['king']-word2vec['man']+word2vec['women']
word2vec.similar_by_vector(result_vector)Output:
[('king', 0.6478992700576782),
('queen', 0.535493791103363),
('women', 0.5233659148216248),
('kings', 0.5162314772605896),
('queens', 0.4995364844799042),
('kumaris', 0.492384672164917),
('princes', 0.46233269572257996),
('monarch', 0.45280298590660095),
('monarchy', 0.4293173849582672),
('kings_princes', 0.42342400550842285)]
In above example we have queen at the second place and princess here, but why do we get the king again? Apparently this is because the man and woman vectors are not strong enough to move the king vector enough, so king vector dominates the others, and the resulting point is still very close to king. What we need is another method. We can use most_similar_cosmu function which stands for cosine multiplication, and this method tends to balance the influence of each words. We can pass the words in arrays of positives and negatives.
word2vec.most_similar_cosmul(positive=['king', 'women'],negative=['men'])Output:
[('queen', 0.8980512022972107),
('monarch', 0.852789580821991),
('princess', 0.8153557181358337),
('crown_prince', 0.8029592037200928),
('monarchy', 0.8002360463142395),
('queendom', 0.7904359102249146),
('sultan', 0.7819830775260925),
('kings', 0.781066358089447),
('Mohammed_Zahir_Shah', 0.780860960483551),
('absolute_monarch', 0.7797768712043762)]
This seems correct. Similarly you can try glove and fast-text. All three models will be able to find the queen in the first place.
You can try additional examples such as, Paris − France + Japan lead to Tokyo. Similarly, summer − hot + cold often results in winter.
However, this behavior is not consistent across all cases. For latte – milk + water, we might expect americano—or at least a concept related to coffee—but the resulting vector is often unrelated. Likewise, doctor − hospital + teacher might be expected to yield school, yet the output is typically far from this intuition.
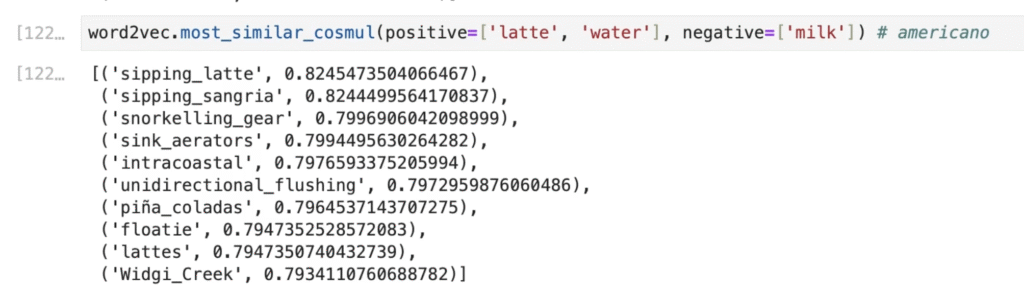
These examples highlight an important limitation: treating word embeddings as if they support reliable mathematical reasoning is insufficient for many NLP tasks. Instead of relying solely on vector arithmetic, word embeddings are more effectively used as input features to neural networks. Such models can learn task-specific patterns and are widely applied to problems like text classification, named entity recognition, and sentiment analysis.
Limitations and Solutions
Word embeddings are significant improvements in NLP, but they come with limitations. Let’s talk about some of them and the potential solutions.
Embeddings like Word2Vec and GloVe assign a single vector to each word. So what about the words with multiple meanings? For example, apple might mean the fruit or the tech company. The solution is to generate dynamic representations of the words based on the context. Models like GPT and BERT produces different vector for a word based on its usage in a sentence.
Another problem might be fixed corpus and fixed vocabulary which limits the model’s ability to handle new words. Using subwords like in fastText can solve this issue. These models represent words as character engrams so they can also generate vectors for words that are not in the training data.
Bias is one of the biggest challenges for word embeddings. Biased AI models are created because of biased training data. A well‑known example is gender bias. Words like nurse and teacher are closer to the word woman. Whereas, words like professor and engineer are closer to the word man. This means that we cannot use that kind of models for job application interviews. There is no other solution than modifying the process or the training data, but research is ongoing in this area.
Lastly, training word embeddings requires significant time and computational resources. Well, we can use pre‑trained models just like we did, and we can also finetune them with small datasets for specific applications.
Conclusion
To conclude, we read about embedding models, which turn text (and other data) into numeric vectors that capture meaning and relationships so machines can compare and reason about them.We also covered how classic word embeddings (Word2Vec, GloVe, fastText) improved NLP but have limits around context, new words, bias, and training cost.Finally, we saw that modern NLP often relies on pre‑trained and contextual embeddings as inputs to larger neural models to get richer, task‑specific representations.