Last Updated on March 21, 2026 by KnownSense
Generative AI becomes far more powerful when you stop thinking in single prompts and start thinking in systems. Instead of asking ChatGPT, Claude, or Copilot one question at a time, imagine an AI system that can plan tasks, call APIs, retain context over time, and refine its output. In other words, the shift from isolated prompting to system design unlocks advanced automation, stronger reasoning, and domain-specific intelligence.pecific intelligence.
Four techniques drive this evolution: model adaptation, tool use and function calling, retrieval-augmented generation (RAG), and AI agents. Moreover, each one builds on the previous. Together, they form the foundation for building robust, production-grade Gen AI solutions. So let’s start with the first building block — teaching an LLM to speak your language.
Tailoring LLMs to Your Domain: Model Adaptation
Large language models are powerful generalists. They train on massive datasets and, as a result, handle a wide range of tasks out of the box. But what happens when you need domain-specific accuracy? For instance, medical terminology, legal clauses, and financial regulations often trip up general models. That is where model adaptation becomes useful. In essence, you start with a general-purpose model and adapt it to perform better on your data and tasks without rebuilding it from scratch. In short, you customize rather than recreate.
Full Fine-Tuning vs. Efficient Fine-Tuning
Currently, two main approaches exist:
Full fine-tuning retrains the entire model. Although it delivers strong results, it demands significant compute and cost.
PEFT (Parameter-Efficient Fine-Tuning), on the other hand, updates only a small portion of the model’s weights. Think of it as adding lightweight adapter modules that teach the model what it needs without retraining the entire system.
LoRA and Its Variants
Among the most popular PEFT methods, LoRA (Low-Rank Adaptation) stands out. It introduces a lightweight trainable layer that helps steer the model toward a new task— just enough to guide behavior without heavy lifting. Furthermore, newer variations like QLoRA and AdaLoRA make this process even lighter and more efficient. As a result, you can personalize models to your industry, team, or product without massive infrastructure costs.
In both cases, adaptation can reduce hallucinations, improve accuracy, and increase trust in the model’s output. However, one critical principle still applies: garbage in, garbage out. High-quality training data matters far more than sheer volume. In fact, a few hundred well-curated examples can make a model far more useful than millions of irrelevant ones.
Tool Use and Function Calling: Giving LLMs External Access
Here is a quick experiment: ask an LLM when its training data ends. The answer reveals a cutoff date — clearly not current. Now ask it about today’s weather in your city. Surprisingly, it answers correctly. So how does this work?
The answer is simple — the LLM reached beyond its training data. Specifically, it accessed the outside world. This capability — calling external functions, querying APIs, and browsing the web — can transform a chatbot into a more capable, action-oriented system.
What Is Function Calling?
Function calling is a developer pattern that lets an LLM decide when to stop generating text and instead request an external action. The workflow follows a simple loop — decide, act, observe — and works like this:
- Define your tools: You provide the LLM with descriptions and schemas for the functions it can call. For example, a
get_weatherfunction that accepts alocationparameter. - The LLM decides: When a user asks a question, the model determines whether a tool is needed and, if so, which function to call and with what arguments. Rather than answering directly, it returns a structured request such as:
function: get_weather, argument: "Paris". - Your application acts: Your code executes the function, retrieves the result, and passes it back to the model.
- The LLM responds: Finally, the model incorporates the tool’s output into a complete, informed answer.
OpenAI’s GPT API supports this pattern natively, and many other modern LLM platforms offer similar interfaces. The key insight is that you control which tools the model can access — it never executes arbitrary code beyond the functions you expose.
Why Function Calling Matters
Within that safe sandbox, this loop unlocks three key benefits:
- Smarter workflows. Instead of following rigid scripts, the LLM dynamically chooses what action to take next — replacing hand-coded decision logic with flexible reasoning.
- Real-time data. Models can fetch current information such as weather, database records, and live API data, so they no longer rely solely on static training data.
- A bridge to agents: Most importantly, function calling is the enabling technology that powers autonomous AI agents, which we will explore shortly.
So far, we have covered how to adapt a model’s knowledge and how to give it the ability to take action. But there is still a gap: how do you feed the model the right information at the right time? That is precisely what RAG addresses.
Smarter Retrieval: How RAG Improves Accuracy and Trust
While tool use lets an LLM act, Retrieval-Augmented Generation (RAG) controls what knowledge the model draws from. Think of it this way: if function calling gives the model hands, then RAG gives it a library card.
In simple terms, you provide the documents, the LLM reads them, and then it answers your questions based on that material. That is RAG at its core.
The Architecture of a Basic RAG System
RAG, or Retrieval-Augmented Generation, is a system that augments an LLM by injecting relevant external context at runtime. Here is how the process works, step by step:
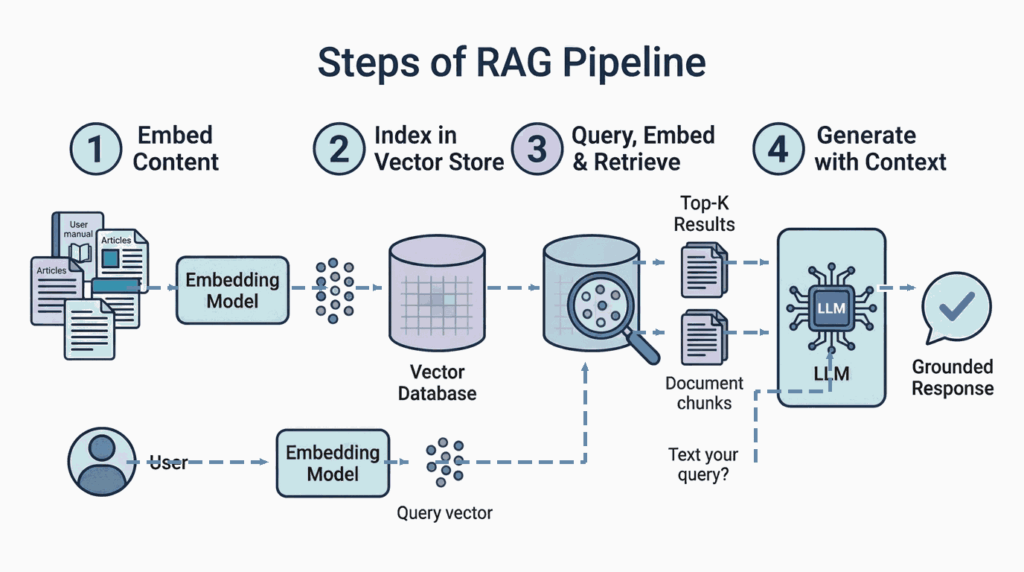
- Embed content. First, convert all reference material — documentation, manuals, knowledge-base entries — into dense vector embeddings using a model like OpenAI’s `text-embedding-3` or similar.
- Index in a vector store. Then, store these embeddings in a vector database that supports similarity search via nearest-neighbor queries.
- Query, embed, and retrieve. When a user submits a query, the system also embeds it and compares it to stored vectors. As a result, the top-k most relevant results (using cosine similarity or dot product) are returned.
- Generate with context. Finally, the retrieved documents or chunks are added to the LLM’s prompt. The model then uses them to produce a grounded, up-to-date response.
In short, the system follows the pattern search → read → respond. Because of this design, the model generates answers that go far beyond its original training data.
Why Vector Databases Matter for Semantic Search
Traditional search relies on exact keyword matches. RAG pipelines, however, need something deeper: semantic similarity. That is why vector databases are essential — they search by meaning, not just terms.
- Semantic matching: For example, “renewable energy” and “solar power” yield similar vector representations — even though the words differ entirely.
- Scale: These databases can handle millions of vectors and return nearest matches in milliseconds.
- Easy integration: Modern vector databases often offer APIs, hybrid search (combining text and vectors), and metadata filters (by time, document type, and more).
Popular tools include FAISS (Facebook), Weaviate, and Pinecone — all optimized for high-dimensional vector indexing and fast approximate nearest-neighbor search. Ultimately, in a RAG setup, the speed and quality of your semantic search depend heavily on your indexing strategy and vector database performance.
How RAG Minimizes Hallucinations
LLMs hallucinate when they lack the right information in context. Consequently, they fill gaps by generating plausible-sounding content based on training patterns. After all, an LLM is fundamentally a sophisticated autocomplete — a probability machine. RAG helps solve this problem by grounding the LLM in retrieved documents relevant to the user’s query.
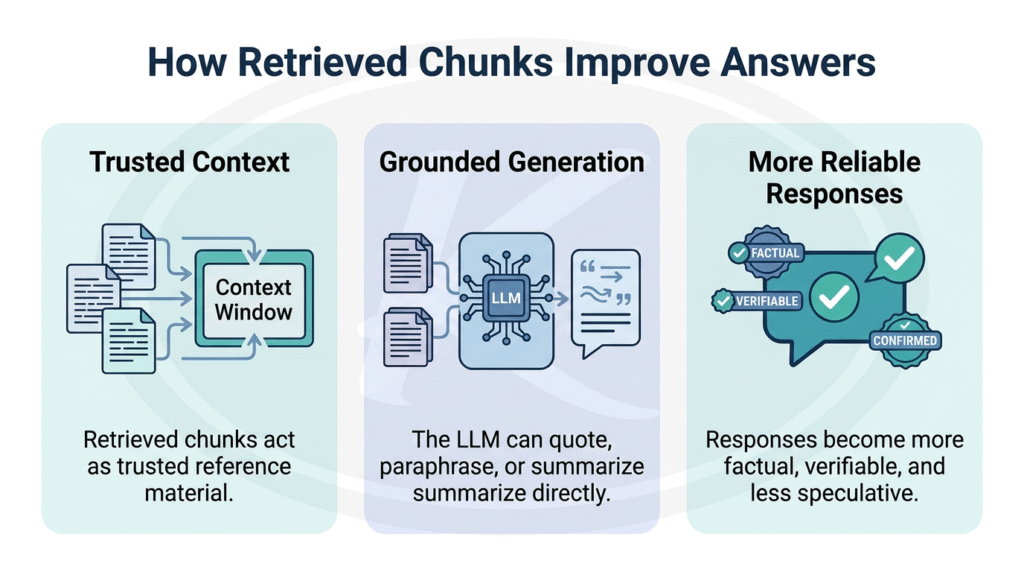
For instance, a legal assistant built on RAG cites specific clauses from actual contracts instead of guessing. This matters enormously in regulated environments — finance, healthcare, compliance — where trust, transparency, and citation are non-negotiable.
Sources Build Trust
RAG also boosts trust because the model bases answers on real documents. It can include references, quotes, and source citations so users can verify every answer. For example, systems like Bing AI and ChatGPT’s deep research features increase trust by showing sources and citations alongside their answers.
Because of these advantages, RAG has quickly become the go-to strategy for reliable AI assistance. Many organizations already deploy Gen AI solutions that retrieve up-to-date information on the fly.
Now we have all the ingredients: a model that understands your domain (adaptation), can take action in the real world (tool use), and draws from the right knowledge (RAG). The final piece brings everything together — AI agents that orchestrate all of these capabilities autonomously.
AI Agents: Building Autonomy into Gen AI Systems
Everything we have discussed so far — model adaptation, function calling, and RAG — converges in AI agents. These are LLM-powered systems that combine planning, tool use, and retrieval to accomplish complex goals with limited human intervention.
What Makes an Agent Different?
Unlike single-turn chatbots, agents go beyond answering one question at a time. Instead, they exhibit three core capabilities:
- Planning: They break complex, multi-step goals into smaller subtasks.
- Execution: They use tools, memory, and external systems to complete those subtasks through the function-calling pattern discussed earlier.
- Collaboration: Furthermore, they coordinate with other agents to solve problems. For example, a researcher agent finds information, and a writer agent uses it to produce a report.
Multi-Agent Collaboration in Practice
To see this in action, consider orchestration frameworks and automation tools such as OpenAI’s agent tooling, n8n, and Make. These tools orchestrate multiple agents working together. For instance, picture a full team of AI agents on a project:
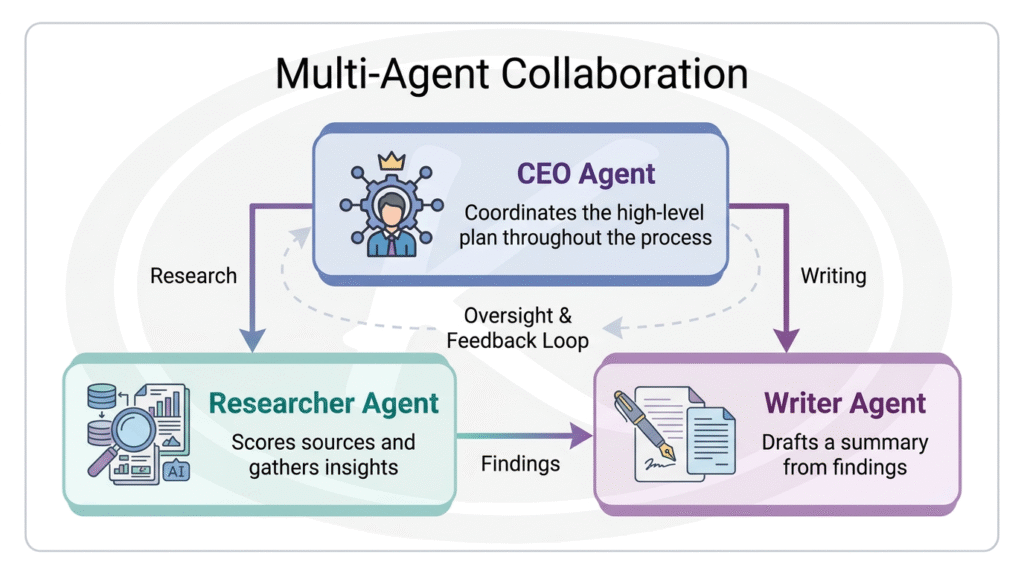
This kind of multi-agent collaboration already powers business intelligence, workflow automation, complex research assistants, and multi-step planning systems.
Why Agents Matter Right Now
Task automation is one of the most impactful areas in technology today. For the first time, headcount is no longer the primary growth metric for startups. Instead, companies increasingly focus on revenue per employee — precisely because agents automate tasks that once required large teams. As a result, every major AI provider invests heavily in agent capabilities. The industry clearly sees autonomous AI agents as the next frontier.
Despite their potential, AI agents come with real challenges. Without careful guardrails, an agent can get stuck in a loop or drift off track. When that happens, it can consume resources quickly, which directly increases cost for you or your company. In addition, making agents reliable in production often requires strong prompt design, evaluation, feedback tuning, observability, and safety controls.
In other words, this is very much a frontier: exciting, but not plug-and-play magic. You are not just building tools; you are building systems that behave more like digital coworkers. Nevertheless, these agent systems, driven by planning, tool use, and iterative reasoning, mark the next wave of intelligent automation: agentic AI.
Conclusion
So what does all of this mean for you? By combining model adaptation, tool use, RAG, and agents, you can design AI solutions that truly augment your team’s capabilities. Generative AI is no longer just a chatbot answering questions. Rather, it is a system that can understand domain-specific context, retrieve the right information, take actions, and assist in real workflows. Understanding these core concepts gives you more control, confidence, and clarity when working with these powerful tools. It helps you move from simply using Gen AI tools to intentionally designing with them, while also improving your prompting, debugging, and decision-making. Just as importantly, this knowledge helps you recognize risks such as hallucinations, overconfidence, and unsafe behavior, so you can build more trustworthy systems. As AI continues to evolve across text, image, code, and video, these foundational ideas will remain relevant, making them one of the best long-term investments you can make in your learning.