Last Updated on December 25, 2025 by KnownSense
Understanding the architecture of NLP models matters because, even though we can now call powerful pre‑trained models with just a few lines of code, we still need to know how they are trained and what they are actually doing under the hood. This knowledge helps us choose the right type of model for a task—for example, a classification model that outputs a single label for an input (such as sentiment) versus a sequence model that produces a structured sequence of outputs (such as a translation or token‑level tags). It also makes it easier to debug issues, reason about limitations, and safely adapt or fine‑tune these models for real applications.
Text Classification Tasks
Common NLP classification tasks include sentiment analysis, which predicts whether a piece of text expresses a positive, neutral, or negative attitude; spam detection, which decides if a message should be flagged as spam or treated as legitimate; and topic categorization, which assigns documents to high‑level themes such as politics, sports, or economics. These examples all follow the same pattern: the model reads raw text as input and outputs a discrete label that represents the most likely category for that text.
Neural networks for text classification
To build a text classification model, we start by preparing a dataset of text with labeled sentiments. We then use a deep learning model to learn from this data. The most commonly‑used neural networks for text classification are CNNs, RNNs, LSTMs, and transformers. After the training, our model will be able to classify even the unseen text samples.
Sentiment Analysis Model
Before start working on sentiment analysis model, Let’s understand some basic terms and steps to make the hand’s on easy.
PyTorch
An open‑source deep learning framework (primarily in Python) that makes it easy to build, train, and debug neural networks. It uses a tensor data structure (like NumPy arrays on CPU/GPU) and dynamic computation graphs, so models feel like regular Python code and are simple to experiment with. It’s widely used in research and production.
Hugging Face Tokenizers
It is a library that converts text into numbers in a fast, modern, and reliable way so that machine-learning models can understand text.
LSTM (Long Short-Term Memory)
A special type of Recurrent Neural Network (RNN – a type of neural network designed to work with sequences) that reads words in sequence, keeps memory of important words, forgets irrelevant information, and handles long sentences effectively. An LSTM sentiment classifier is a neural network that processes text word by word, understands the context, and determines whether the sentiment expressed is positive or negative.
Sentiment Analysis Steps
Let’s walk through it slowly and intuitively, step by step, so you can clearly see what happens to the text at each stage in an LSTM sentiment classifier.
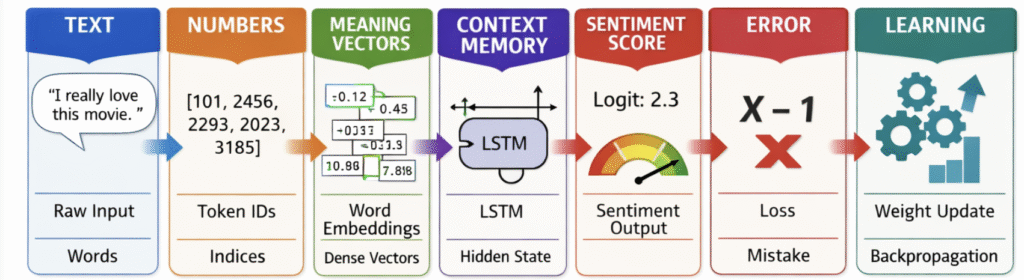
- Text
"I really love this movie"
This is a raw text. Neural networks cannot understand text directly, so we must convert it into numbers. - Tokenizer (Hugging Face)
A tokenizer splits text into words or subwords, handles punctuation, casing, and unknown words, builds a vocabulary, and maps each token to a numerical ID.i → 101
Now the sentence becomes a list of integers. At this stage, the model still does not understand sentiment.
really → 2456
love → 2293
this → 2023
movie → 3185 - Embedding Layer (Word2Vec initialized)
The embedding layer maps token IDs to dense vectors that capture semantic meaning. Word2Vec initialization means the model starts with pretrained word vectors, which are further fine-tuned during training for the sentiment task. - LSTM
As already mentioned above , it processes a sentence word by word in sequence, maintains memory of previous words, learns what information to keep or forget, and captures long-term dependencies.
The hidden state is the output of an LSTM because it encodes the learned features and context of the sequence up to the current time step. It is called hidden because it exists inside the network and is used internally to process information.Example reasoning:
Sees "i" → neutral
Sees "really" → intensifier
Sees "love" → strong positive
Remembers "love" till the end - Linear Layer (Fully Connected)
The linear layer transforms the LSTM’s hidden state into a raw score (logit) using a weighted sum and bias, which is later converted to a probability. It returns single number (for binary sentiment) or multiple numbers (for multi-class)Example:
This number is not a probability yet. It’s just a raw score. To get a probability, you apply a function like sigmoid (for binary) or softmax (for multi-class)
logit = W · h + b
logit = 2.3 - Loss Function (BCEWithLogitsLoss – Binary Cross-Entropy with Logits)
It’s purpose is to measure how well the model’s prediction matches the true label (positive or negative sentiment). It Guides the model during training. The optimizer tries to minimize this loss so predictions get closer to the true labels.
How it works:- Converts the logit into a probability internally using sigmoid.
- Compares it with the true label (0 or 1).
- Computes the loss — a number that tells the model “how wrong” it is.
- backward() & Optimizer
Backward computes gradients of the loss with respect to all model parameters using backpropagation and then tells the optimizer how much to change each weight to reduce the loss.
How it works:- The error (difference between predicted and true label) flows backward through the network.
- Gradients are calculated for: Embedding layer weights, LSTM weights, Linear layer weights
- Training loop
In each training loop, the model tokenizes input, converts tokens to embeddings, processes them with LSTM, computes a logit, calculates loss, backpropagates gradients, and updates weights using an optimizer.
Conclusion
In conclusion, we understand the key steps—from tokenization and embeddings to LSTM processing and loss optimization—provides a clear picture of how text classification and sentiment analysis work. Each stage plays a crucial role in transforming raw text into meaningful predictions, enabling models to effectively interpret and evaluate sentiment.